TÀI LIỆU BÀN GIAO KỸ THUẬT DỰ ÁN LGSP SERVICE
Hệ thống trục liên thổng của tỉnh
Nền tảng: WSO2 Micro Integrator 4.4.0
- CHƯƠNG I: TỔNG QUAN VÀ THIẾT KẾ HỆ THỐNG LGSP
- TRANG 1: Bối cảnh dự án và Tầm nhìn tích hợp
- TRANG 2: Công nghệ và Các thành phần lõi
- TRANG 3: Phân tích bài toán liên thông LGSP - NGSP
- TRANG 4: Chi tiết Cơ sở dữ liệu vận hành (Core Schema)
- CHƯƠNG II: KIẾN TRÚC VÀ CÁC LOẠI HÌNH DỊCH VỤ
- TRANG 1: Dịch vụ API REST (Gateway Layer)
- TRANG 2: Tầng Dịch vụ Dữ liệu (Data Services - DSS)
- TRANG 3: Hệ thống Proxy và Cầu nối Hệ thống cũ (Legacy)
- TRANG 4: Trục Tin nhắn RabbitMQ & Kafka (Messaging Layer)
- CHƯƠNG III: CƠ CHẾ ĐỒNG BỘ DỮ LIỆU TỰ ĐỘNG
- TRANG 1: Sơ đồ luồng hoạt động tổng quát (Sequence Diagram)
- TRANG 2: Bộ máy điều phối Task (Orchestrator)
- TRANG 3: Phân tích Logic Đánh giá Cron Expression (JS Engine)
- TRANG 4: Thực thi và Cập nhật trạng thái (Runner)
- CHƯƠNG IV: CẤU HÌNH VÀ MÔI TRƯỜNG VẬN HÀNH
CHƯƠNG I: TỔNG QUAN VÀ THIẾT KẾ HỆ THỐNG LGSP
Sơ bộ hệ thống LGSP
TRANG 1: Bối cảnh dự án và Tầm nhìn tích hợp
1.1. Hiện trạng và Thách thức
Trong kỷ nguyên số, các cơ quan nhà nước tại địa phương thường vận hành các hệ thống phần mềm độc lập (Silos). Điều này dẫn đến việc dữ liệu bị chia cắt, không đồng bộ và gây khó khăn cho người dân khi thực hiện thủ tục hành chính liên thông. Dự án LGSP (Local Government Service Platform) ra đời để giải quyết các nút thắt này.
1.2. Tầm nhìn của trục LGSP
- Trở thành bộ não điều phối: Kết nối mọi yêu cầu từ Cổng Dịch vụ công tới các CSDL quốc gia.
- Chuẩn hóa thông tin: Đảm bảo mọi bản ghi (người dùng, doanh nghiệp, văn bản) đều tuân theo cấu chuẩn chung của Bộ Thông tin & Truyền thông.
- Bảo mật và Giám sát: Mọi giao dịch đi qua trục đều được kiểm soát quyền truy cập và lưu vết (Logging) phục vụ hậu kiểm.
TRANG 2: Công nghệ và Các thành phần lõi
2.1. Nền tảng WSO2 Micro Integrator (MI) 4.4.0
Hệ thống sử dụng WSO2 MI - một nền tảng mã nguồn mở mạnh mẽ nhất thế giới về ESB. Các ưu điểm chính:
- Tốc độ xử lý: Khả năng xử lý hàng ngàn giao dịch/giây với cơ chế non-blocking I/O.
- Linh hoạt: Hỗ trợ mọi loại giao thức từ REST, SOAP đến các File System, Kafka, RabbitMQ.
- Microservices-ready: Đóng gói gọn nhẹ trong Docker container, dễ dàng triển khai trên cụm K8s.
2.2. Các thành phần phụ thuộc (Middleware)
- Broker (RabbitMQ): Đóng vai trò làm "kho đệm" cho các văn bản điện tử quan trọng. Đảm bảo tin nhắn không bị mất khi hệ thống đích quá tải.
- Streaming (Kafka): Sử dụng để đẩy các sự kiện log về trung tâm phân tích dữ liệu lớn.
- Database (MySQL): Lưu trữ cấu hình runtime và nhật ký vận hành.
TRANG 3: Phân tích bài toán liên thông LGSP - NGSP
3.1. Mô hình kết nối Liên thông Quốc gia (NGSP)
Dự án thực hiện vai trò là Gateway trung gian giữa Địa phương và Trung ương:
- Hướng đi lên (Upstream): Các app địa phương gọi API qua LGSP -> LGSP thực hiện ký số/xác thực -> Gửi lên NDXP/NGSP.
- Hướng đi xuống (Downstream): Dữ liệu từ các Bộ/Ngành gửi về qua NGSP -> LGSP tiếp nhận -> Phân phối về đúng phòng ban/sở ngành tương ứng.
3.2. Đảm bảo tính tin cậy tuyệt đối (Guaranteed Delivery)
Đối với văn bản điện tử (EDXML), hệ thống không chỉ gọi API mà còn thực hiện:
- Lưu kho (Store): Lưu payload vào Message Store.
- Thử lại (Retry): Nếu gửi thất bại, Message Processor sẽ tự động thử lại theo cơ chế Exponential Backoff (thời gian giãn cách tăng dần).
- Cảnh báo (Alert): Nếu sau N lần thử vẫn thất bại, hệ thống sẽ chuyển vào Queue lỗi để Admin xử lý thủ công.
TRANG 4: Chi tiết Cơ sở dữ liệu vận hành (Core Schema)
Hệ thống yêu cầu các bảng dữ liệu sau trong ESB_DB để có thể vận hành các tính năng nâng cao:
4.1. Quản lý trạng thái Khóa (sync_lock)
Bảng này cực kỳ quan trọng để đảm bảo tính duy nhất của các tiến trình đồng bộ (Task).
- Cấu trúc SQL:
-
CREATE TABLE `sync_lock` ( `lock_key` varchar(50) NOT NULL COMMENT 'Mã khóa duy nhất của Task', `is_locked` tinyint(1) DEFAULT '0' COMMENT '1: Đang bận, 0: Sẵn sàng', `locked_at` datetime DEFAULT NULL COMMENT 'Thời điểm bắt đầu chạy', PRIMARY KEY (`lock_key`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
4.2. Quản lý Lập lịch Task động (job_schedule)
Cho phép Admin cấu hình lịch chạy mà không cần sửa code WSO2.
- Cấu trúc SQL:
CREATE TABLE `job_schedule` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`service_code` varchar(100) NOT NULL COMMENT 'Mã nghiệp vụ (Vd: DM_TTHC)',
`cron_expression` varchar(50) NOT NULL COMMENT 'Ví dụ: 0 0 * * * ? (Chạy mỗi giờ)',
`sequence_name` varchar(100) NOT NULL COMMENT 'Tên Sequence xử lý chính',
`sync_endpoint_path` text COMMENT 'URL API đích',
`last_run` datetime DEFAULT NULL COMMENT 'Lần chạy thành công cuối cùng',
`status` tinyint(1) DEFAULT '1' COMMENT '1: Kích hoạt, 0: Tái kích hoạt',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;4.3. Quản lý Nhật ký truy cập (api_logs)
- Cấu trúc SQL:
CREATE TABLE `api_logs` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`api_name` varchar(100) DEFAULT NULL,
`request_time` datetime DEFAULT NULL,
`log_level` varchar(20) DEFAULT NULL,
`message` text DEFAULT NULL,
`serviceCode` varchar(100) DEFAULT NULL,
`systemCode` varchar(100) DEFAULT NULL,
`headers` text DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CHƯƠNG II: KIẾN TRÚC VÀ CÁC LOẠI HÌNH DỊCH VỤ
Cấu trúc dự án và loại hình hiện có
TRANG 1: Dịch vụ API REST (Gateway Layer)
1.1. Cấu trúc và Vị trí
Các định nghĩa API nằm tại: src/main/wso2mi/artifacts/apis. Mỗi API trong dự án LGSP đóng vai trò là một Gateway, thực hiện bảo mật, ghi log và điều phối yêu cầu.
1.2. Luồng xử lý tiêu biểu (Ví dụ: GuiNhanVanBan API)
Hệ thống sử dụng các Mediator mạnh mẽ để xử lý nghiệp vụ:
- Xác thực Header: Lấy các thông tin như
activityid,servicetype,messagetypetừ Transport Header. - Xác thực Đơn vị (CheckUnitCodeDBS): Sử dụng
<dataServiceCall>để kiểm tra mã hệ thống (SystemCode) của đơn vị gửi. Nếu không tồn tại, API sẽ trả về lỗi ngay lập tức. - Lưu trữ tin nhắn (Message Store): Sử dụng lệnh
<store messageStore="EDXMLMessageStore"/>để đưa payload vào hàng đợi RabbitMQ thay vì gửi trực tiếp, giúp tăng khả năng chịu tải và tin cậy.
1.3. Cơ chế Logging Tập trung
Mọi API đều gọi đến DatabaseLogSequence và ResultLogSequence để:
- Lưu vết vào bảng
api_logs. - Ghi lại thông tin người dùng (Client IP), payload request và response code.
TRANG 2: Tầng Dịch vụ Dữ liệu (Data Services - DSS)
2.1. Khái niệm và Vai trò
Dự án sử dụng các file cấu hình .dbs (tại src/main/wso2mi/artifacts/data-services) để trực tiếp thao tác với cơ sở dữ liệu mà không cần viết code Java/Spring.
2.2. Các dịch vụ trọng yếu
- SyncTaskService.dbs: Quản lý toàn bộ vòng đời của các Task đồng bộ. Cung cấp các thao tác
getTasks,insertTask,updateLastRun. - syncLockDataService.dbs: Chứa các logic nghiệp vụ về Khóa (Lock), giúp đảm bảo tính toàn vẹn khi có nhiều tác vụ chạy song song.
- danhMucTheoMa.dbs: Một dịch vụ quy mô lớn (91KB) cung cấp hàng trăm API tra cứu danh mục dựa trên các bảng dữ liệu chuyên ngành.
2.3. Ưu điểm triển khai
- Cấu hình động: Thay đổi câu lệnh SQL dễ dàng mà không cần biên dịch lại ứng dụng.
- Xác thực tập trung: Sử dụng xác thực ở mức API Gateway sau đó mới gọi vào DSS.
TRANG 3: Hệ thống Proxy và Cầu nối Hệ thống cũ (Legacy)
3.1. Proxy Services
Dành cho các hệ thống backend cũ sử dụng giao thức SOAP/XML. Các Proxy này nằm tại src/main/wso2mi/artifacts/proxy-services.
- Thực hiện chuyển đổi Payload từ JSON sang XML (qua Payload Factory) để gọi vào các hệ thống cũ.
- Trải qua các bộ lọc (Filter) để loại bỏ các thẻ XML thừa trước khi trả về cho Client.
3.2. Điều hướng Động (Dynamic Routing)
Sử dụng switch mediator dựa trên thuộc tính REST_METHOD (GET, POST, PUT, DELETE) để quyết định gọi URL tương ứng, giúp giảm thiểu số lượng API cần quản lý.
TRANG 4: Trục Tin nhắn RabbitMQ & Kafka (Messaging Layer)
4.1. Hệ thống RabbitMQ (Reliable Messaging)
Được cấu hình thông qua MessageStore và MessageProcessor:
- Message Store:
EDXMLMessageStorekết nối trực tiếp tới Queue trên RabbitMQ. - Message Processor:
SendEdoc2đóng vai trò là "Worker" thức dậy định kỳ để đẩy tin nhắn đi. - Cơ chế Retry: Nếu hệ thống đích (NGSP/Bộ ngành) lỗi 503, tin nhắn sẽ quay lại Queue và thử lại sau N giây.
4.2. Hệ thống Kafka (Event Streaming)
Sử dụng KafkaProducerAPI để đẩy các sự kiện dữ liệu lớn:
- Đẩy dữ liệu nhật ký hội thoại hoặc log hệ thống.
- Cung cấp dữ liệu cho hệ thống giám sát thời gian thực của tỉnh.
CHƯƠNG III: CƠ CHẾ ĐỒNG BỘ DỮ LIỆU TỰ ĐỘNG
Xử lý đồng bộ dữ liệu lớn
TRANG 1: Sơ đồ luồng hoạt động tổng quát (Sequence Diagram)
Hệ thống đồng bộ của LGSP không chạy theo lịch cứng mà chạy theo cơ chế "Quét và Đánh giá" (Scan & Evaluate) dựa trên cấu hình linh hoạt trong Database.
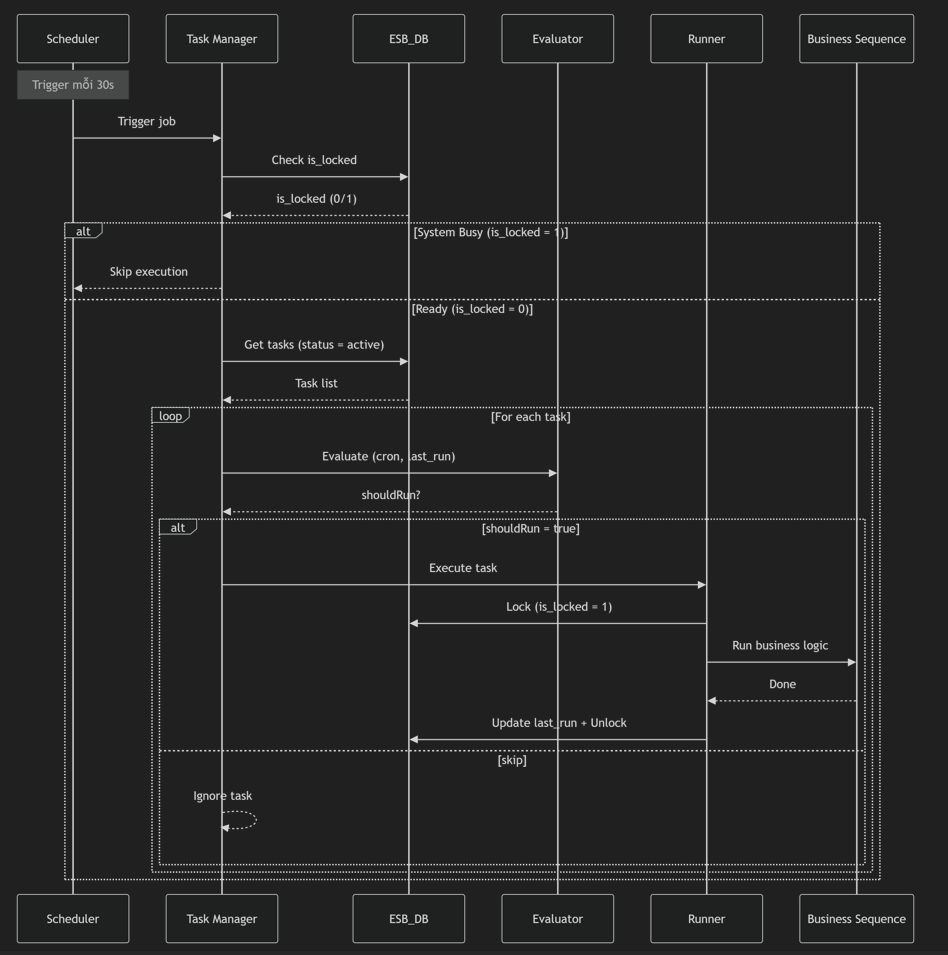
Sau khi Task kích hoạt, hệ thống sẽ đi qua một chuỗi các Sequence có nhiệm vụ chuyên biệt để đảm bảo tính an toàn và linh hoạt.
1.1. Bước 1: Quản lý Luồng (ManagerEvaluateTasksSequence)
Đây là sequence "cửa ngõ". Nhiệm vụ chính:
- Kiểm soát concurrency: Sử dụng
dataServiceCalltới bảngsync_lock. Nếu có một tiến trìnhRunTaskSequencetrước đó chưa kết thúc (vẫn đangis_locked=1), nó sẽ dừng ngay lập tức. - Phân tách dữ liệu: Sử dụng mediator
<iterate>để biến danh sách Task từ Database thành từng gói tin độc lập cho mỗi Task.
1.2. Bước 2: Đánh giá Cron (EvaluateSingleTaskSequence)
Với mỗi Task được tách ra, bộ Evaluator sẽ:
- Trích xuất
cron_expression(ví dụ:0 */15 * * * ?- chạy mỗi 15 phút). - Sử dụng Script Mediator (JavaScript) để tính toán thời gian chạy tiếp theo.
- Kết quả: Nếu thỏa mãn điều kiện thời gian, nó sẽ nạp biến
shouldRun = truevào Message Context.
1.3. Bước 3: Bộ định tuyến động (RunTaskSequence)
Sequence này đóng vai trò là "Cầu giao điện" tổng. Nó thực hiện:
- Khóa hệ thống: Gọi
lockSyncđể ngăn các Task khác nhảy vào chiếm dụng tài nguyên. - Điều hướng (Switch Mediator): Dựa vào tên Sequence lưu trong database (
sequence_name), nó sẽ điều hướng tới logic nghiệp vụ thật sự:MultiEndpointSyncSequence: Đồng bộ hóa đa điểm tiêu chuẩn.DongBoDVLTSequence: Đồng bộ dữ liệu dịch vụ lưu trú (Sử dụngBatchInsertMediatorđể nạp dữ liệu lớn).DongboVBDenEdocSequence: Chuyên trách đồng bộ Văn bản điện tử.
- Hoàn tất: Sau khi nghiệp vụ chạy xong, nó cập nhật
last_runvào DB và thực hiệnunlockSync.
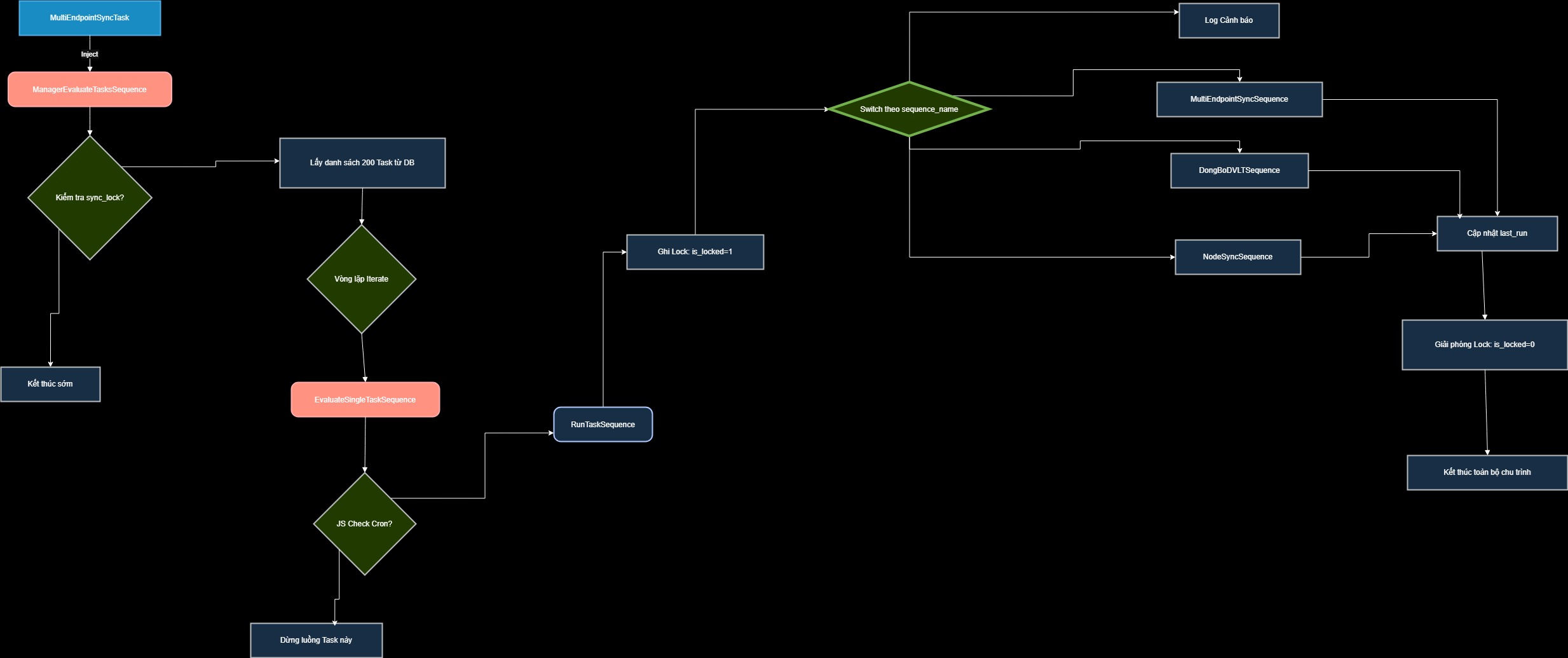
1.4. Cơ chế nạp dữ liệu động (Dynamic Batch Insert)
Trong dự án LGSP, thay vì viết hàng trăm câu lệnh INSERT cho hàng trăm loại danh mục khác nhau, chúng ta sử dụng cơ chế Dynamic SQL thông qua 2 Stored Procedure phối hợp. Cơ chế này cho phép hệ thống tự động nhận diện cấu trúc tệp JSON trả về từ đối tác và nạp vào bảng tương ứng trong Database.
1.4.1. Sơ đồ luồng xử lý tại Database
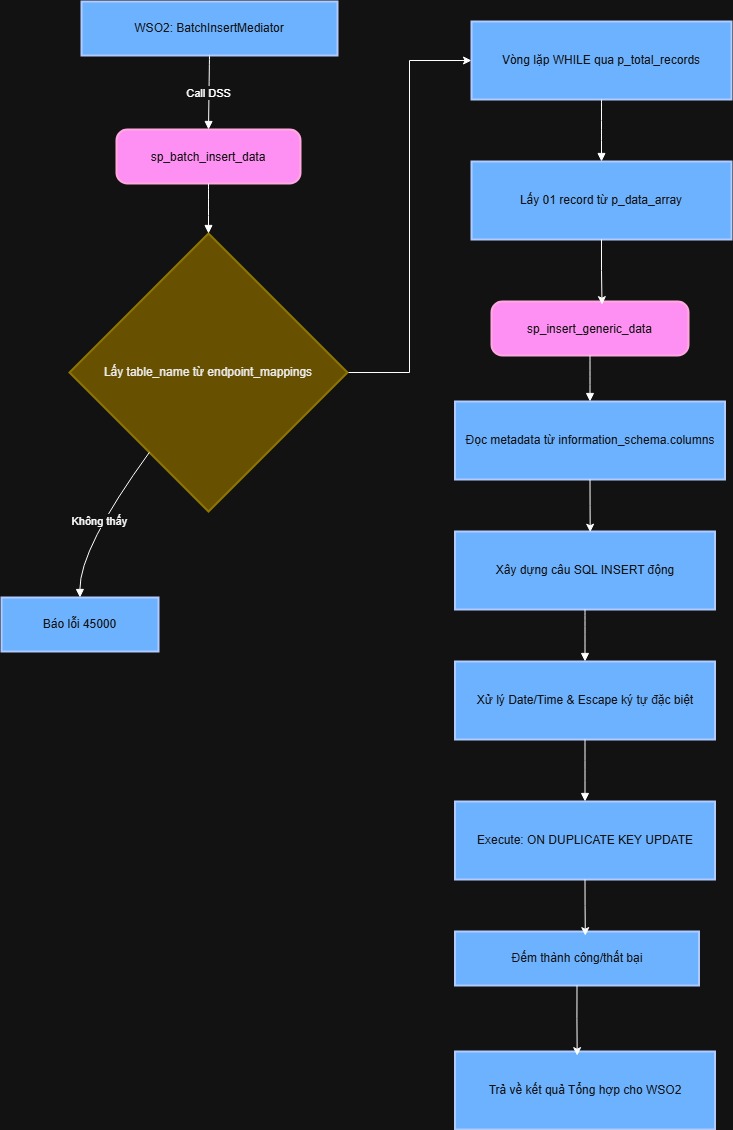
1.4.2. Phân tích Procedure bộ điều phối: sp_batch_insert_data
Nhiệm vụ chính: Phân rã mảng dữ liệu (Array Parsing).
- Tham số đầu vào:
p_endpoint_path(để xác định bảng đích),p_data_array(chuỗi JSON khổng lồ chứa hàng trăm bản ghi),p_total_records. - Cơ chế chịu lỗi (Fault Tolerance): Procedure sử dụng
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION. Điều này cực kỳ quan trọng: Nếu trong 100 bản ghi có 1 bản ghi bị lỗi dữ liệu, Procedure sẽ không dừng lại mà chỉ tăng biếnv_error_count, sau đó tiếp tục xử lý bản ghi tiếp theo. - Kết quả trả về: Một tập bản ghi (ResultSet) chứa:
status(success, partial, error),messagechi tiết vàrecord_countthực tế đã nạp thành công.
1.4.3. Phân tích Procedure thực thi động: sp_insert_generic_data
Đây là chìa khóa của sự linh hoạt. Nó thực hiện Tự động nhận diện cấu trúc bảng (Table Discovery).
- Bước bóc tách dữ liệu: Procedure kiểm tra xem JSON có bọc trong thẻ
$.datahay không để lấy đúng nội dung cần thiết. - Bước ánh xạ cột (Dynamic Mapping):
- Nó truy cập vào
information_schema.columnsđể xem bảng đích có những cột nào, kiểu dữ liệu là gì. - Nếu cột trong JSON không có trong Database -> Tự động bỏ qua (Giúp hệ thống không bị chết khi đối tác thêm trường dữ liệu mới).
- Nó truy cập vào
- Xử lý kiểu dữ liệu:
- Tự động nhận diện các cột
DATE,DATETIME,TIMESTAMPđể sử dụng hàmSTR_TO_DATE. - Tự động thay thế (
REPLACE) các ký tự đặc biệt như dấu nháy kép, dấu gạch chéo để chống lỗi cú pháp SQL.
- Tự động nhận diện các cột
- Cơ chế Upsert: Sử dụng cú pháp
ON DUPLICATE KEY UPDATE updated_at = NOW().- Nếu bản ghi đã tồn tại (trùng Primary Key): Cập nhật thông tin mới nhất.
- Nếu chưa có: Chèn mới.
- Điều này giúp dữ liệu trong kho địa phương luôn đồng bộ với trục Quốc gia mà không gây trùng lặp.
1.4.4. Các bảng cấu hình phụ thuộc
Để 2 Procedure này hoạt động, bạn cần cấu hình bảng mapping
CREATE TABLE endpoint_mappings (
id INT AUTO_INCREMENT PRIMARY KEY,
endpoint_path VARCHAR(200) NOT NULL, -- Đường dẫn API (Vd: /api/v1/don-vi)
table_name VARCHAR(100) NOT NULL, -- Tên bảng trong Database
status TINYINT DEFAULT 1 -- 1: Kích hoạt
);TRANG 2: Bộ máy điều phối Task (Orchestrator)
2.1. MultiEndpointSyncTask (Điểm khởi đầu)
Nằm tại: src/main/wso2mi/artifacts/tasks/MultiEndpointSyncTask.xml.
- Class:
org.apache.synapse.startup.tasks.MessageInjector. - Cơ chế: Task này không chứa logic đồng bộ. Nó đóng vai trò "còi báo động" định kỳ cứ mỗi 30 giây (hoặc cấu hình) sẽ đẩy một thông điệp vào bộ máy xử lý.
2.2. ManagerEvaluateTasksSequence (Bộ quản lý)
Đây là "bộ não" điều phối toàn bộ quá trình:
- Kiểm tra Khóa (sync_lock): Hệ thống gọi
syncLockDataService/getLock. Nếu một luồng đồng bộ khác đang chạy, luồng mới sẽ tự động hủy để tránh tình trạng "Race Condition" (nhiều tiến trình cùng ghi vào một bảng dữ liệu). - Lấy cấu hình Task: Truy vấn lên tới 200 Task đang ở trạng thái kích hoạt (
status='1') từ bảngjob_schedule. - Lặp (Iterate): Sử dụng thẻ
<iterate>của WSO2 để chia nhỏ danh sách Task cho các luồng xử lý song song, tối ưu hóa hiệu suất CPU.
TRANG 3: Phân tích Logic Đánh giá Cron Expression (JS Engine)
3.1. Tại sao cần JavaScript?
WSO2 MI mặc định không có hàm so sánh thời gian với biểu thức Cron phức tạp (như 0 0/15 * * * ?). Do đó, dự án sử dụng JavaScript (Nashorn Engine) để gọi trực tiếp các thư viện Java của Quarkz.
3.2. Chi tiết mã nguồn Evaluator
Tại EvaluateSingleTaskSequence.xml, hệ thống thực hiện các bước:
- Lấy
cron_expressionvàlast_run(chuỗi string) từ Database. - Chuyển đổi
last_runsang đối tượngDatecủa Java. - Sử dụng class
org.quartz.CronExpressionđể tính toán thời điểm chạy tiếp theo (nextRun). - So sánh: Nếu
nextRunnhỏ hơn hoặc bằng thời gian hiện tại (now), hệ thống xác định Task này đã đến hạn chạy (shouldRun = true).
TRANG 4: Thực thi và Cập nhật trạng thái (Runner)
4.1. RunTaskSequence (Bộ thực thi)
Ngay khi nhận được tín hiệu shouldRun = true, Runner sẽ thực hiện:
- Locking: Gọi
lockSyncđể đánh dấu hệ thống đang bận thực hiện nghiệp vụ nặng. - Dynamic Call: Sử dụng
sequence_namelấy từ DB để gọi đến Sequence xử lý nghiệp vụ thật sự (Vd:MultiEndpointSyncSequence). Điều này cho phép mở rộng hệ thống bằng cách chỉ cần thêm Sequence mới và cấu hình vào DB mà không cần sửa code Runner.
4.2. Hoàn tất và Giải phóng
Sau khi nghiệp vụ đồng bộ hoàn thành (thành công hoặc thất bại):
- Cập nhật Last Run: Lưu timestamp chạy thành công cuối cùng vào DB để lượt quét sau tính toán đúng.
- Unlock: Giải phóng khóa (
is_locked = 0) để các đợt quét định kỳ tiếp theo có thể thực hiện các Task khác.
CHƯƠNG IV: CẤU HÌNH VÀ MÔI TRƯỜNG VẬN HÀNH
Cấu hình tích hợp các công nghệ
TRANG 1: Toàn tập cấu hình Deployment.toml
Tệp deployment/deployment.toml là file cấu hình duy nhất của WSO2 Micro Integrator. Mọi thông số từ Port, Memory đến Database đều được quản lý tại đây.
1.1. Cấu hình Server cơ bản
- [server]: Thiết lập
offset. Nếu trong mạng có nhiều node WSO2, mỗi node cần có một offset khác nhau để tránh xung đột cổng. - [management_api]: Cấu hình User/Password để các công cụ bên ngoài (như VS Code hoặc MI Dashboard) có thể kết nối và quản lý.
1.2. Cấu hình Connection Pool (HikariCP)
Mặc định WSO2 MI sử dụng HikariCP để quản lý kết nối Database. Các tham số tối ưu cần lưu ý:
max_active: Số lượng kết nối tối đa. Với LGSP, giá trị này nên đặt từ 30-50 tùy theo tải.min_idle: Duy trì ít nhất 5-10 kết nối chờ sẵn để tăng tốc độ phản hồi.
TRANG 2: Quản lý Datasources và Kết nối Cơ sở dữ liệu
Dự án LGSP yêu cầu 3 nguồn dữ liệu chính được định nghĩa trong block [[datasource]]:
2.1. Nguồn dữ liệu ESB_DB
Đây là nơi lưu trữ "trạng thái" của trục tích hợp.
- Vai trò: Quản lý bảng
job_schedule,sync_lock,api_logs. - Driver: Sử dụng
com.mysql.cj.jdbc.Driver(MySQL 8+). - Lưu ý: Datasource này phải trùng tên (
id = "ESB_DB") với khai báo trong các file.dbs.
2.2. Nguồn dữ liệu LGSP_NOIBO
- Vai trò: Chứa các bảng danh mục đồng bộ về (Đơn vị hành chính, TTHC...).
- Địa chỉ: Thường nằm trên cụm DB chuyên dụng có tốc độ truy xuất cao.
2.3. Nguồn dữ liệu NIFI_DB
- Vai trò: Phục vụ cho việc đẩy dữ liệu báo cáo sang hệ thống Apache Nifi.
TRANG 3: Broker và Messaging Configuration (RabbitMQ/Kafka)
3.1. Cấu hình RabbitMQ (Transport)
Để sử dụng được mô hình "Store-and-Forward" (Gửi văn bản điện tử), bạn cần kích hoạt:
- [transport.rabbitmq.sender]: Cho phép WSO2 MI đẩy tin vào Queue.
- [transport.rabbitmq.listener]: Cho phép WSO2 MI lắng nghe và xử lý tin nhắn từ Queue.
- Tham số: Cần khai báo đúng IP/Port của RabbitMQ Server và Virtual Host (thường là
/).
3.2. Cấu hình Kafka (Streaming)
Dùng cho việc đẩy Log Analytics:
- bootstrap.servers: Danh sách các Kafka Broker (IP:Port).
- key.serializer/value.serializer: Thường dùng
StringSerializer.
TRANG 4: Bảo mật, Keystores và Certificates
LGSP là hệ thống chính quyền, yêu cầu bảo mật HTTPS và mã hóa dữ liệu.
4.1. Quản lý Keystores
Nằm tại repository/resources/security/:
- wso2carbon.jks: Chứa chứng chỉ SSL của Server LGSP (Dùng cho HTTPS).
- client-truststore.jks: Chứa các Public Key của đối tác (NGSP, Cổng DVC Quốc gia) để WSO2 có thể gọi API HTTPS của họ mà không bị lỗi SSL.
4.2. Bảo mật mật khẩu (Secret Management)
Thay vì viết mật khẩu DB dạng Clear-text trong deployment.toml, ta nên dùng công cụ Secure Vault của WSO2 để mã hóa:
- Chạy lệnh
ciphertool.shđể mã hóa mật khẩu. - Sử dụng cú pháp
$secret{alias}để gọi mật khẩu trong file cấu hình.